DALMOOC episode 6: Armchair Analyst
 |
| Week 6 CCK11 blog connections |
I think week 3 and week 4 blend together for me. For example, in looking at analytics the advice, or recommendation, given is that an exploration of a chunk of data should be question driven rather than data-driven. Just because you have the data it doesn't necessarily mean that you'll get something out of it. I agree with this in principle, and many times I think that this is true. For instance, looking back at one of our previous weeks, we saw the analytics cycle. We see that questions we want to ask (and hopefully answer) inform what sort of data we collect and potentially how we go about collecting it. Just having data doesn't mean that you have the data that you need in order to answer specific questions.
On the other hand, I do think that there are perfectly good use cases where you might be given a data-dump and not have any questions. Granted, this makes analysis a bit hard, like it did for me the last couple of weeks. This data (anonymized CCK11 data, and sample evaluation data for Tableau) didn't really mean much to me, so it was hard to come up with questions to ask. On another level I've been disconnected from the data, so it's not personally meaningful as a learner (CCK11 data was anonymized), and since I didn't have a hand in organizing, offering, and running CCK11 it's not as useful for me as a designer. However as a researchers, I could use this data dump to get some initial hypotheses going. Why do things look the way they look? What sort of additional, or different, data do I need to go out and test my hypothesis? How might I analyze this new data? As such, a data-driven approach might not be useful for answering specific questions, however it might be a spark to catalyze subsequent inquiry into something we think might be happening; Thus helping us formulate questions and go out and collect what we need to collect to do our work.
So, for example, I have just started my EdD program at Athabasca University. I have a lot of ideas running through my head at the moment as to what I can research for a dissertation in 3 years†. As I keep reading, I keep changing and modifying my thoughts as to what do to. I may be able to employ learning analytics as a tool in a case study research approach. For instance, I teach the same course each spring and fall semester, an online graduate instructional design course on the design and instruction of online courses (very meta, I know). The current method of teaching is quite scaffolded, and as Dragan was describing last week (or this week?) I tend to be the central node in the first few weeks, but my aim is to just blend in as another node as the semester progresses. This process is facilitated through the use of the Conrad & Donaldson Phases of Engagement Model (PDF).
So, one semester I can use this model to teach the course and another semester I might create an Open Online Course based on the principles of connectivism and run the course like that. I'd have to make some changes to the content to make sure that most course content be Open Access content, that way I would be eliminating some variables, but let's assume I've done this and I'm just testing Connectivism vs "regular" graduate teaching (whatever that is). I can then use SNA, as one of my tools, to see what's happening in these two course iterations. I can see how people are clustering together, forming communities (or not), how they are engaging with one another and so on. This analysis could be an element of the study of efficacy of connectivism as employed in a graduate course‡.
On the other side of things, if I were to just stick with my traditional online course, I could still use SNA to improve my course. One of the things that I notice is that some groups tend to form and stay together early on in the semester. These seem to be informal groups (person X commenting on person Y's posts throughout the semester more than they do for person Z). Since the semester is 13 weeks long, a JIT dashboard of course connections would be useful to both encourage people to find study groups, but also to engage more with people that they don't normally engage in. People who usually post late in the forums (at least in my experience) don't often get many responses to their posts, which is a real pity since they often bring some interesting thoughts to the discussion.
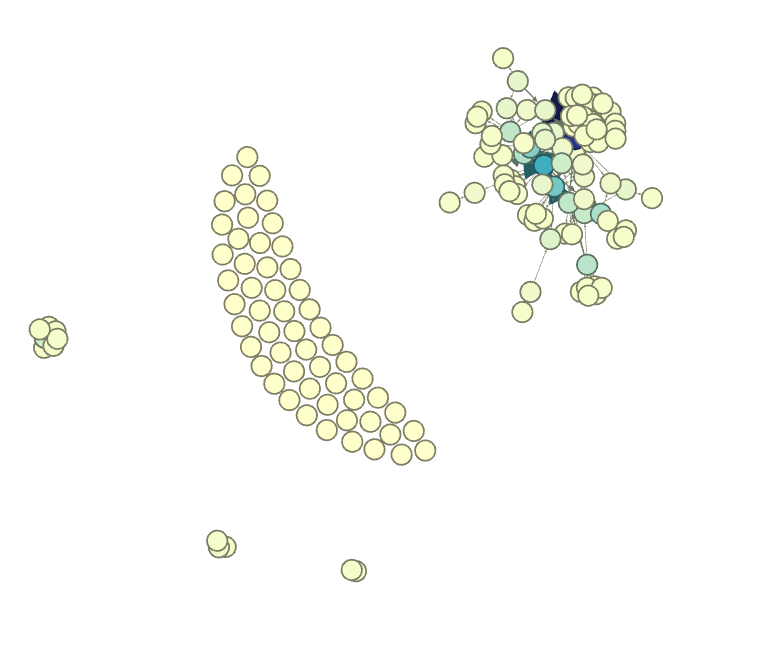
A good example of this is the image above, the CCK11 blogs from Week 6. I see a number of disconnected blogs. Were these blogs never read (as measured by the click-through rate on the gRSShopper Daily)? Were they never commented on by anyone? Some of the blogs may not speak to anyone in the course, but in a course of 1131 participants (citation), assuming a 80% drop off by week 6, that's still around 200 people active in the MOOC, why is not one connecting with these posts, and can we do anything to spur participation? Maybe an adopt a blog post campaign? This is also where the quantitative aspects of SNA mesh with the qualitative aspects of research. Here we could also do an analysis of what gets picked up (those connected nodes) to what doesn't get picked up, and do an analysis of the text. This might help us see patterns that we can't see with SNA alone.
That's it for week 4. And now I am all caught up. Welcome to week 5! Your thoughts on Week 4?
SIDENOTES:
† The more I think about this, the more I am learning toward a pragmatic dissertation rather than a "blow your mind" dissertation. I see it more as an exercise that will add some knowledge in this world, but given that doctoral dissertations are rarely cited, I am less interested in going all out, and more interested in demonstrating pragmatics of research through a topic of interest. Thoughts on this? I definitely don't want to stick around in dissertation purgatory.
‡ I'm pretty sure that someone (or quite a few) have written about this, especially with regard to CCK08, but let's just roll with this example.


Comments
is the data that we want and seek, it all depends on the questions behind the
data. Purpose of data is to get answers for question after all. That is my
principle too, I collect data for my research essay that way and I don’t pay to write
college essay , I do it on my own, after collecting data after I
understood the topic of my essay. However if we do not know about the subject a
tall and don’t know what questions we want answers for, data driver approach could
come in handy. You can read stuff, then make hypothesis and make questions for
which your data should provide answers.